
What if AI had corporate culture?
How AI software engineering agents perform differently based on structuring interactions as big tech org charts.

“There will be more AI agents than people in the world.” —Mark Zuckerberg
Multi-agents are taking over. Research shows that AI systems with 30+ agents out-performs a simple LLM call in practically any task (see More Agents Is All You Need), reducing hallucinations and improving accuracy.
But how should agents actually work with each other? While exploring methods to improve AI performance on software engineering tasks, I stumbled upon an idea: What if we structured AI agent interactions like the org charts of big tech companies?
Here are some key takeaways I learned after organizing groups of AI agents as if they were in companies like Apple, Microsoft, Google, Amazon, and more:
Companies with multiple “competing” teams (i.e. competing to produce the best final product) like Microsoft and Apple outperformed centralized hierarchies.
Systems with single points of failure (for example, one leader making important decisions) like Google, Amazon, and Oracle underperformed.
Big-tech organizational structures had a modest but noticeable impact on problem-solving capability.
Software and big tech organization theory
Previous attempts to improve AI software engineering capabilities included throwing more agents at SWE-bench (a popular benchmarking tool for AI software engineers). However, simply increasing the number of agents did not lead to dramatic improvements in resolution rates (see the SIMA agent). How else can you make AI agents better at software engineering?
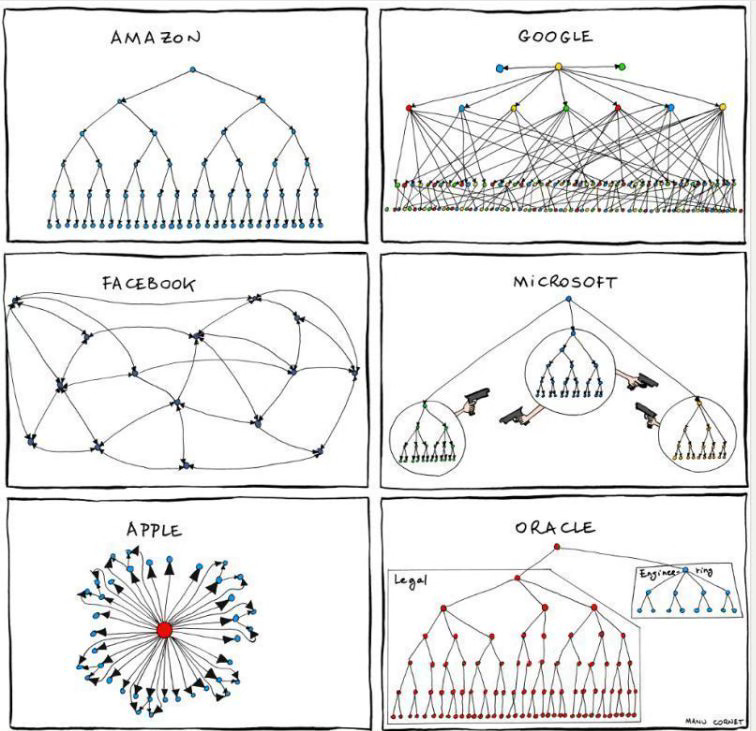
Cue three weeks ago, when I stumbled across a post by James Huckle about Conway’s Law: “Software and product architecture is destined to be a reflection of the organizational structure that created it”. He presented an illustration that shed light on the dramatised organisational structures of Amazon, Google, Facebook, Microsoft, Apple, and Oracle, proposing the idea that just like humans in big tech companies, multi-agent communication structures could shape problem-solving approaches. I was inspired to put James’s hypothesis to the test on SWE-bench instances.
The experimental setup
I organized AI agents as if they were in different corporations, evaluating six different organization structures on a 13 instance “mini” subset of SWE-bench-lite (to increase the speed of evaluation and for financial reasons 😃). When building the six organizations, I based the multi-agentic organizational design off of some core observations:
Amazon: A binary tree with one “manager” at the top level. To replicate this, I had a large number of agents that performed code repository search, and a single agent that performed the repository update in the end.
Google: A similar tree structure to that of Amazon, except that there are a lot more connections between intermediary layers. I replicated this with aggregations of all agent results within a single layer, passing that to agents in the next layer.
Facebook: Lack of a hierarchical structure, but still a web-like organization with many connections between agents. I modified the original agentic design by adding more possibilities for transitions between different agents.
Microsoft: Competing teams each with their own hierarchies. Essentially, I repurposed the structure in Amazon (decreasing # of agents) and chose the “best” solution out of three separate runs (each run having a small tweak to the hierarchy) using a vector similarity voting method.
Apple: I also interpreted this structure as many small competing teams each with their own minimal structure. I used the same “best solution” method as Microsoft, except had many more runs without an agent hierarchy (and different transitions for each run).
Oracle: Here, there were two different teams, a larger “legal” binary tree with a smaller engineering tree. I interpreted the legal team as the agents that are searching the code repository and retrieving crucial context, while the engineering team composed of agents that actually wrote code. The structure for both teams was similar to that of Amazon, with a single agent at the top coordinating information passing between “legal” and “engineering”.
Results and SWE-bench-docker
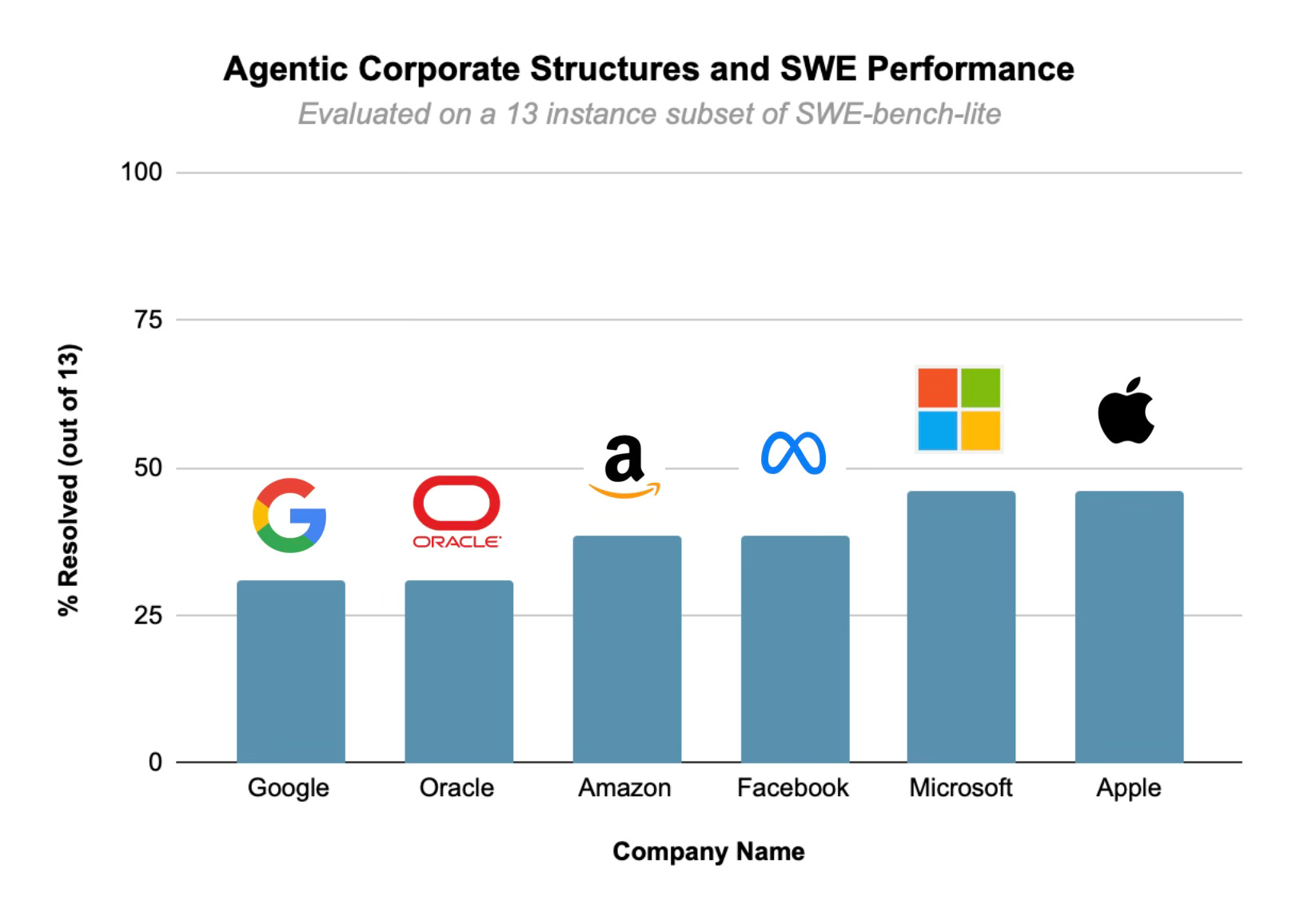
To evaluate each set of patches on SWE-bench, I used the dockerized SWE-bench evaluation provided by the SWE-bench team. I’ve shared my results below:
An analysis on org chart performance
Here are some observations I made on how different corporate structures affected performance:
Competitive teams increase chances of success. The two top performers (Microsoft and Apple) both had multiple teams that were competing to resolve an issue, while other companies seemed to have one gigantic team generating a single patch. Multiple teams allow for increased diversity of problem-solving approaches, increasing the probability of resolving an issue.
Structures with single-point failures didn’t do as well. When I say single-point failures, I mean companies with high-level managers/agents that could completely alter the run results (companies like Google, Amazon, and Oracle). A common issue when orchestrating interactions between multiple agents is the case where one agent fails—leading to potential issues where an agent could change the course of a team’s problem-solving strategy. Companies with single-point failures are susceptible to these kinds of issues.
Additionally the top two performers, Microsoft and Apple, happened to be the two largest tech companies (by market cap) in the world. It turns out that the organizational structures that seem to work best in the real world also work well for AI agents.
What’s next? My thoughts on advancements in SWE-bench
Looking at the results, the impact of different corporate structures on this mini-benchmark was to be expected (a difference of 1 or 2 instances). In general, it seems that throwing more agents at an issue or changing the way those agents are organized (whether it’s hierarchical or more connections between agents) will lead to marginal improvements in performance on a task as complicated as software engineering.
While More Agents Is All You Need found that accuracy increases by quite a large margin (~20%), performance noticeably flattened after 30 agents on the GSM8K (grade school math). The research also found that tasks with excessive complexity (such as that in SWE-bench) may exceed the model’s reasoning capabilities, leading to diminishing returns on performance gains. I verified this finding in SIMA, achieving at most 2-3% gains over the base architecture (with 40+ agents), and I anticipate these small gains would be consistent in other non multi-agentic architectures as well.
In my opinion, bigger jumps in progress on the benchmark require a change in the actual logical reasoning capability of the agents, or the strategy and methods they can employ (or are given) to actually solve software issues. This can come in the form of more powerful base models (GPT-5?) or a wider array of tools given to the the agents (be it a debugger, linter, or automated testing). It’s the same thing with companies. At the end of the day, if you aren’t hiring smarter employees or giving them better resources, their output won’t improve no matter how you organize them or how many people you have.
However, performance on 13 instances can be quite off from actual performance on the full benchmark, and the differences in just the mini-subset are significant enough that it’s worth focusing on (~50% increase from Google to Apple). Base models or tooling can potentially be limiting factors on agentic software engineering, but playing with agent communication structures (be it in a corporate organization or not) is an issue that absolutely should be tested as base models improve. As James Huckle put it, this concept could become a “critical hyper-parameter” in AI agent design, with different organizational structures being better suited for different tasks.
Thanks for sticking around to the end! For anyone that is interested in continuing experimentation with corporate agentic communications, or exploring different agentic interaction structures, I would love to meet you on Twitter.
These sorts of simulations are a great use case for Large Language Models. Economists should be all over this.
Interesting. We could use this approach to analyze the performance of product development org structures such as the Spotify model, Large Scale Scrum and the Scaled Agile Framework. I would like to see this experiment expanded to include adaptation to new input, since product development is empirical.